




Ten years ago, we designed and built our applications around logic-driven requirements. A user clicks a button and goes to a different screen.
Nowadays, when we think about applications, the first thing that comes to mind is what data they will process and how they will process that data. The second, is how do we observe and audit the data that we have?
This is a shift from logic-driven applications to data-driven applications.
This has created a trend around a concept that's slowly but surely making its way into the mainstream of software engineering: fine-grained authorization.
We used to think about permissions mostly in terms of roles-admin, editor, and viewer. But today, that's no longer enough. The systems we build are more distributed. The users we serve are more sophisticated. And the data we manage is not just growing-it's diversifying, multiplying, and connecting in ways that static role-based logic can't keep up with.
In this article, I want to walk you through the changes I've seen in how we think about access control-why fine-grained authorization is gaining so much traction right now-and what it takes to lift and shift your own model to meet those demands.
TL;DR#
- We've shifted from logic-driven apps to data-driven experiences-and our authorization models need to catch up.
- Fine-grained authorization (FGA) goes beyond roles, factoring in user attributes, resource relationships, and real-time context.
- The rise of microservices, user expectations, and exponential data growth is making FGA essential-not optional.
- You don't need to rewrite everything-you can lift and shift your existing RBAC into finer-grained models like ABAC, ReBAC, and PBAC.
- Tools like FusionAuth and Permit.io make it practical to externalize and scale fine-grained access control.
What Is Fine-Grained Authorization?#
While it's trending now, fine-grained authorization isn't a new concept.
The difference between coarse-grained and fine-grained authorization is quite simple-it's the number of factors we consider when making an access control decision.
Before we dive into those factors, here's a quick reminder:
Authentication is not authorization.
Authentication is the part of the process where we verify identity (you knew that already). We check if the user is who they say they are via passwords, one-time codes, and multi-factor authentication. A Customer Identity and Access Management (CIAM) provider or authentication solution (like FusionAuth) usually handles authentication.
Authorization is the next step in this process. It's about deciding:
"What can this user-or subject-do in our application?"
Or, if we express it in a more technical form, closer to how policies are written:
"Is this user allowed to perform this action on this resource?"
In coarse-grained systems, we answer that question using just one set of inputs:
- A role assigned to the user
- An action being taken
- A resource type being accessed
This works fine for simple questions like:
"Is John allowed to edit documents?"
But it starts to fall apart as complexity grows.
Fine-grained authorization adds more dimensions to that decision. Instead of just relying on a static role or identity, we include:
- attributes of the user (e.g., location, department)
- attributes of the resource (e.g., owner, classification)
- relationships between users and resources
- context (e.g., time of day, date, device, IP address)
Now you're asking:
"If John is located in the U.S. right now, is he allowed to edit documents?"
Or even:
"If John is in the U.S. and the document belongs to a U.S. department, is he allowed to edit it?"
Similar to attributes, we can also define relationships.
We might ask:
"Is John the owner of this particular document?"
Or, in a more complex scenario:
"If this document is related to the Acme project in the marketing department, can John from the sales team view it? Can his manager? How about his solution engineer?"
In this type of fine-grained model, we build relationships between users and resources-and even between resources themselves. This allows us to derive implicit permissions-a user can access something not because we explicitly say so but because the graph of relationships allows it.
These capabilities, which used to be quite niche, are quickly becoming a mainstream necessity in many applications.
With our new understanding of fine-grained authorization, let's look at the trends that make it popular in modern applications.
Trends Driving FGA Forward#
The way we build applications has fundamentally changed, and with that shift, the old way of doing access control-roles and if-then statements scattered through your code-is breaking down.
Below are four trends I've seen pushing fine-grained authorization forward.
Application Architecture - Cloud-Native Everything#
Monoliths or single-server applications are becoming far less common.
We've moved from a world where we had one app, one database, and maybe a frontend, to a world where apps are distributed, asynchronous, and loosely coupled across regions, containers, and services.
In the old days, you could bundle an authorization module into a JAR file and call it from your app.
Today, you need that logic to be streamlined, but still accessible from anywhere-any stack, any runtime, any edge node. This brings up two big requirements:
- The same policies need to be enforced across every service, no matter where or how it runs.
- Your services, written in different languages or running in different clouds, need to consume authorization logic in the same way.
Also, let's not forget it's not just your own code anymore - there's third-party services, dozens of data stores, async jobs, and micro frontends-these all need a shared understanding of "who can do what."
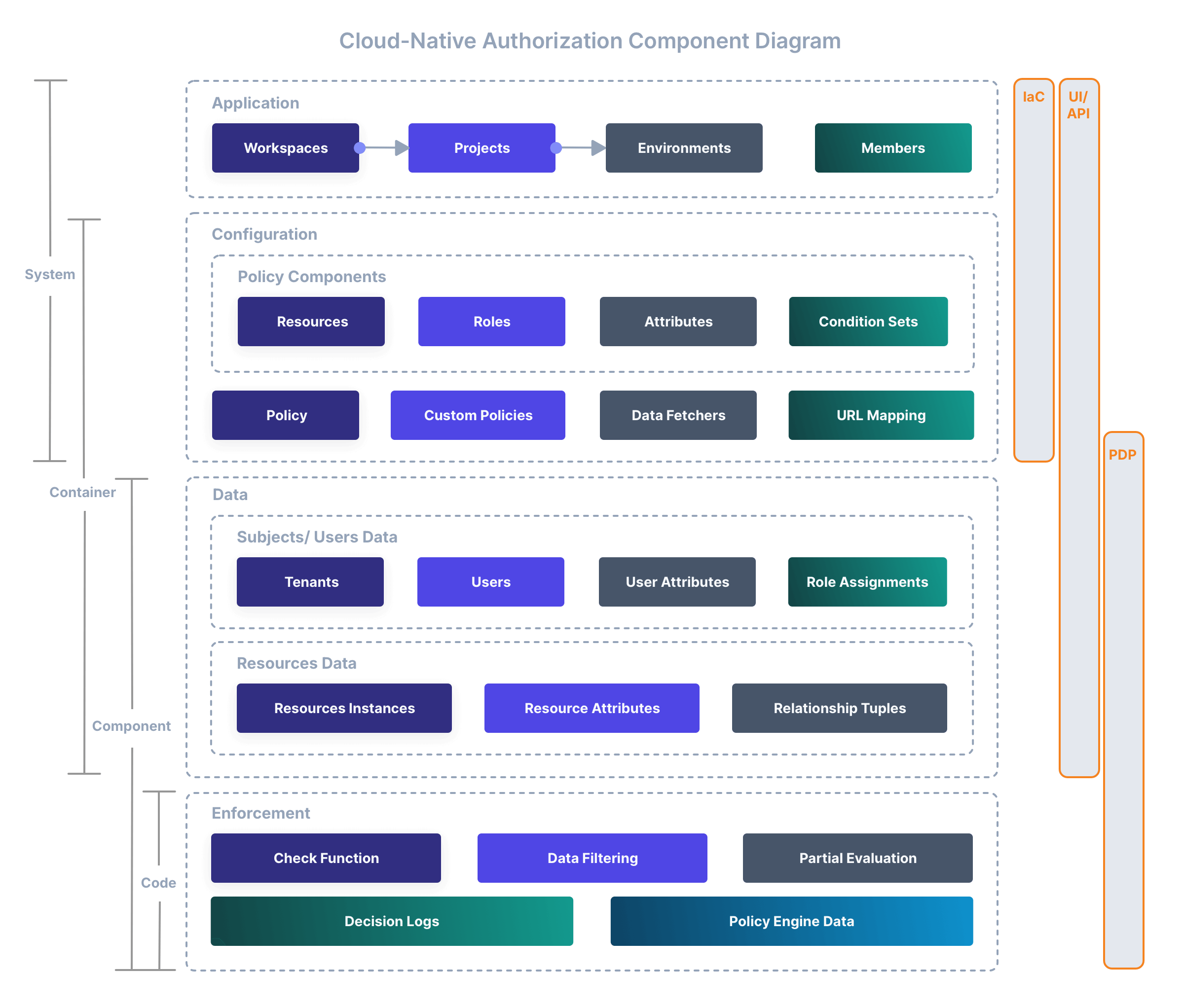
That's why externalizing your authorization into a dedicated, fine-grained service is becoming the de-facto norm. It's not only about centralization-it has to be close to the edge and fast.
Every API call we make requires an authorization decision, and we need some way to decentralize those decisions while still centralizing streamlined policies.
Code stakeholders (It's Not Just Devs Anymore)#
Modern software isn't built by backend engineers alone, with today's applications being touched by a growing cast of stakeholders:
- Frontend developers focused on UX
- DevOps manage deployment and infrastructure
- Product managers configure features and access
- Solution engineers demo environments with elevated permissions
- Support teams need limited access to help users
- Sometimes even non-technical stakeholders edit content or approve workflows
Each of these roles introduces a new layer of access needs beyond your core users. One we have to account for when managing access to data and actions inside our applications.
And when access decisions are scattered across conditionals in your codebase-if user.isAdmin, if user.tenantId === resource.tenantId, if user.email.includes("internal") - that's not really scalable or sustainable.
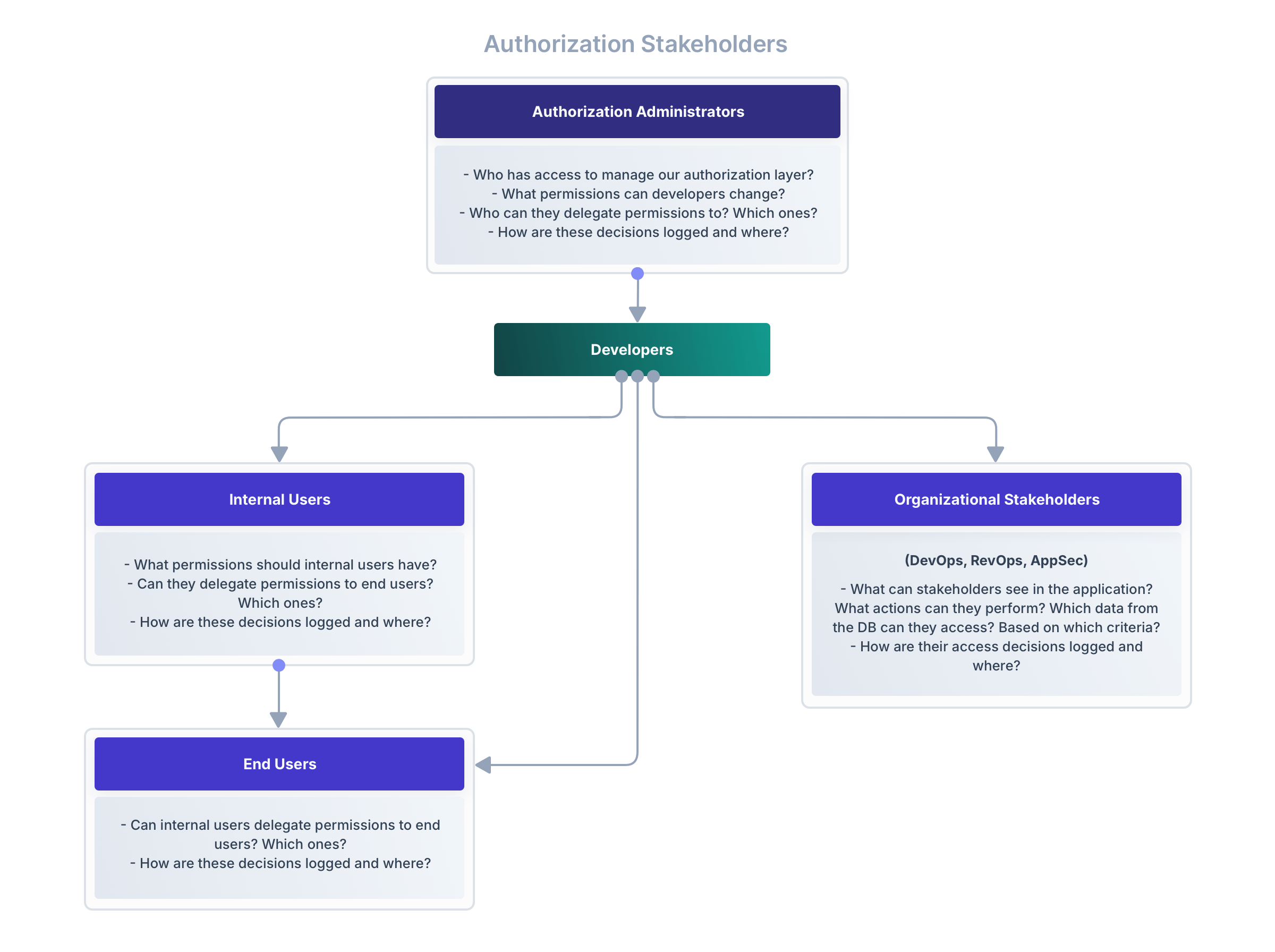
As the number of personas increases, your authorization logic needs to evolve from hardcoded checks to policy-based rules-rules that can be versioned, reused, and make fine-grained decisions in real-time.
More Data, More Problems#
Our applications create and consume a growing amount of data every second-structured, unstructured, real-time, and historical. We're basically not just building apps anymore-we're building data pipelines that happen to have UIs.
Spinning up an app is easy. You've got tools like Vercel, Supabase, and no-code platforms to get something live in hours. But the hard part is "how do you manage access to all that data?"
And not just types of data-specific pieces of data, constantly changing, with context that can't be hardcoded. Coarse-grained authorization can't handle that. You can't just say:
"Users with the report_viewer role can access reports."
Some users should only see reports from their region, others need access during specific hours of the workday, and certain reports contain sensitive data tied to compliance and need to be locked down even further.
You need to inspect the data itself-not just what type it is, but what it contains, who owns it, how it's classified, and where it fits in the broader graph of relationships.
The more data your app touches, the more you need authorization that keeps up-real-time, contextual, and fine-grained.
This shift is what drove companies like Google to pioneer models like Zanzibar-to handle permissions at the scale of Google Ads, YouTube, and Drive, all sharing deeply interconnected data.
The Google Zanzibar paper, released in 2018, describes how they tackled the permissions problem at the scale of a company that processes the largest volume of data on the internet.
Zanzibar popularized the idea of Relationship-Based Access Control (ReBAC) and permission graphs, where users, resources, and relationships are all part of a traversable model that can express permissions dynamically (and thanks to tools like Permit.io and OPAL, you don't need to be Google to implement something similar).
The way Google Zanzibar works is by placing all users and every fine-grained piece of data into a graph, where each piece is a node. The edges between nodes define the permissions in the application.
Here's a relationship graph as represented in the Permit.io UI:
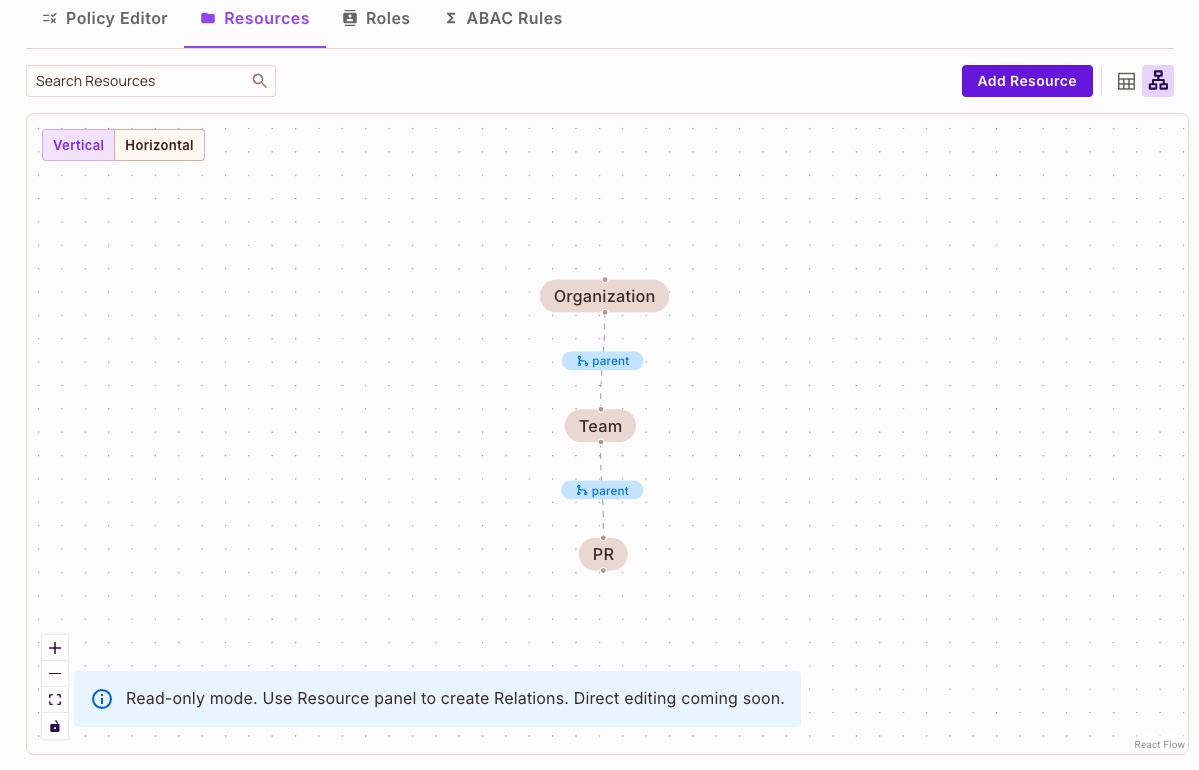
So, for example, if I'm a user connected to my YouTube account, and that account is associated with certain files-and those files are also linked to resources in Google Drive-then I can easily derive permissions to those resources through those relationships.
ReBAC allowed users to traverse and filter large volumes of data in the most fine-grained way possible-and do it very fast. This unlocked endless capabilities when it comes to building rich and adaptable permission models.
Rising User Expectations#
Software users are becoming more and more sophisticated by the day.
They aren't the type of users who join a webinar that shows them how to click on this and that button anymore. They hack and explore the applications they use.
They want more than access-they want ownership, expect collaboration capabilities, and care about privacy.
This new type of user requires permission features you never even dreamed of, and is capable of uncovering data breaches without being technical.
One of the most common premium features in modern applications is secure collaboration-the ability for users to share access or functionality with others: teammates, family members, and friends. It's not just about security-it's about enabling new types of experiences.
If we want users to delegate access or assign roles, we can't just hand them coarse-grained toggles. We need to encapsulate the way our app handles permissions in a way that's shareable, auditable, and contextual.
That means making delegation fine-grained:
- You can't just share a whole workspace-you share a specific document, a specific row, a specific view.
- You need to let users grant access without losing control over what's being shared and why.
- And you need to do it in a way that respects their expectations around privacy and data ownership.
Users are aware of data ownership. They want to make sure that they own their data. They want to make sure that their data is private.
These aren't just feature requests. These are foundational expectations of how modern applications should work.
The more we empower users and the more control we need to give them, the more fine-grained our authorization layer needs to be.
Lift and Shift into Fine-Grained Authorization#
At this point, I hope it's clear: you need something more powerful than roles and hardcoded checks. But that doesn't mean rewriting your entire authorization layer overnight.
If you're building a new application, you're lucky-you can start fresh with a fine-grained, open-source-based authorization service like Permit.io.
Or, if you want to go bigger and roll your own, you can use tools like OPAL (Open Policy Administration Layer) to implement your own setup.
But if you already have a running application with an existing but limited access control layer, you don't have to dump everything and start rebuilding from scratch.
Instead, you can lift and shift-starting from what you already have, and gradually evolving it into something more flexible, future-proof, and fine-grained. Here's how:
Start with Your Current Model, and Don't Reinvent the Wheel#
Most apps already use Role-Based Access Control (RBAC) in some form. That's your foundation. Start there.
RBAC has become almost synonymous with authorization-it's the model most developers think of when they hear the term. In RBAC, permissions are often coarse-grained. You typically just ask:
"Can a user with a particular role perform an action on a certain resource type?"
But you can (and should) go beyond that. Look at your existing roles-admin, manager, viewer-and ask:
- Can this role structure handle multi-tenant scenarios?
- Do I need to assign different roles in different contexts (e.g., per team, per organization)?
- Can users delegate roles to others safely?
Once you've mapped that out, you'll see where RBAC hits its limits-and where you'll need to extend it (we'll get more into that in a bit).
Audit!#
Externalizing authorization allows you to do dry runs. Migrate some policies and add them as shadow decisions to run alongside your current system. Log the decisions. In other words, audit them.
One of the most powerful capabilities of fine-grained authorization systems is their ability to generate detailed decision logs.
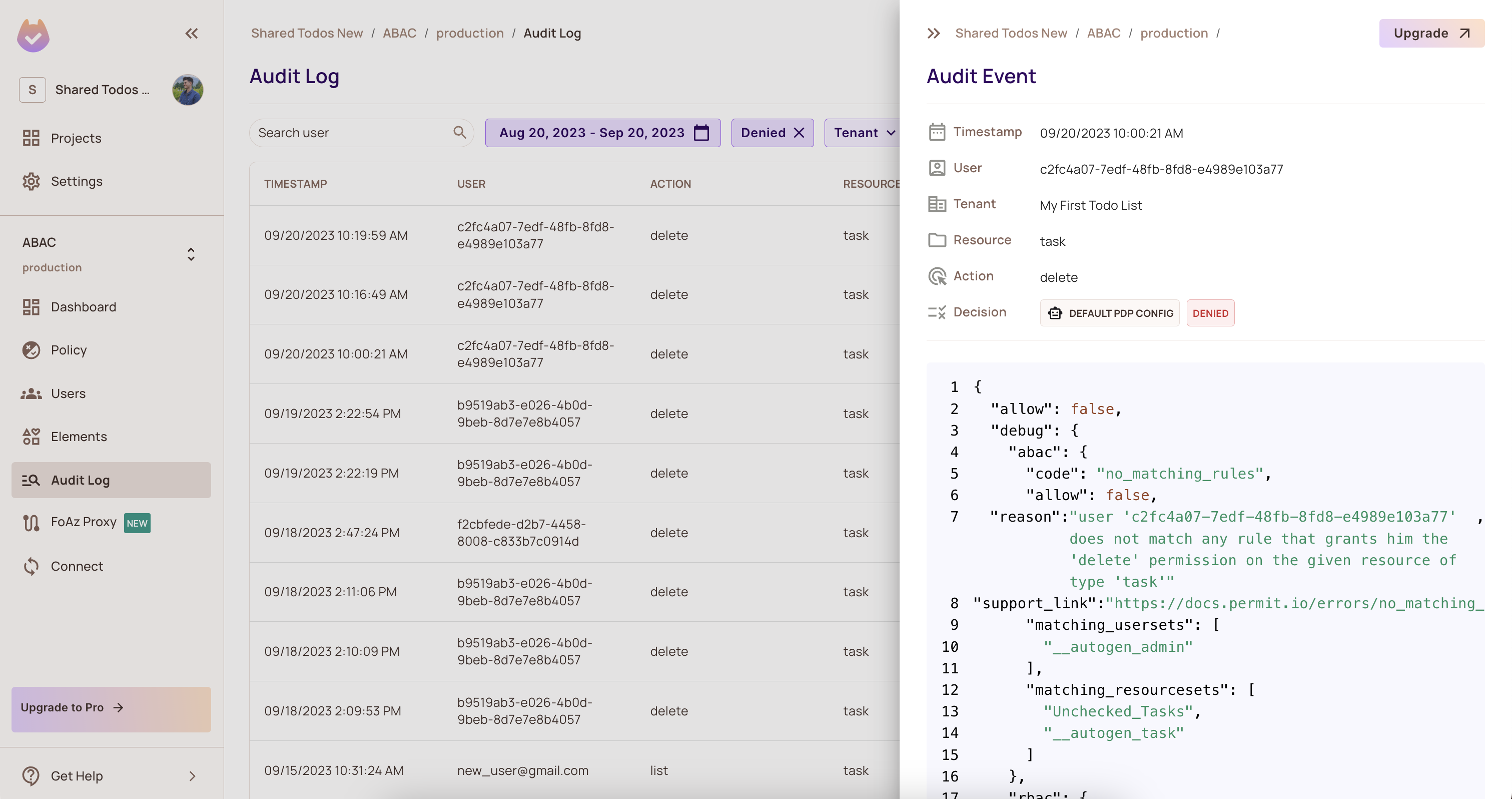
You'll see exactly what happened in your app-who tried to do what, when, and why.
This gives you deep visibility and helps you understand where the new model might fail or need to be restructured.
Know your Options: Understanding Permission Models#
One of the most talked-about topics in fine-grained authorization is the permission models we use. We talked about where RBAC can hit its limits, but how can you expand your authorization model? Well, there are two main ways to do that:
Multi-Tenant Authorization#
When you're building your role-based rules-for example, rules like "a user can access a document"-you can add an additional factor: the role assignment context, such as the tenant the user belongs to.
Including which tenant each user belongs to in your rules or assignment data allows you to assign users to multiple roles across multiple tenants.
Attribute-Based Access Control (ABAC)#
Another way to extend your RBAC model is through ABAC.
What we did in Permit.io is leverage the segmentation of roles and resources from RBAC, and turn them into dynamic conditions.
For example, let's say you have users in the U.S., and you want to segment them by location.
You create a condition like:
attribute.location == "US"Then, you can continue using the same RBAC rules you already have in place-but replace hardcoded segments with dynamic conditions.

You can apply the same logic to resources, segmenting them based on attributes.
That's how you move from role = access to role + context = access.
ReBAC: Relationship-Based Access Control#
With ReBAC, you assign implicit grants to specific instances or entities in the system-based on their relationships with users. This is also something you can extend from RBAC.
Instead of assigning roles only at the resource type level (e.g., "can edit documents"), you can assign roles at the resource instance level (e.g., "can edit this document").
Not only that-you can build a permission graph on top of your instances.
Then, you can continue using the same role assignments and rules as you did with RBAC, but in a fine-grained, relationship-aware way.
This way of thinking-extending RBAC into ABAC and ReBAC-helps you lift and shift your authorization model without forcing your users into something unfamiliar.
Policy-Based Access Control (PBAC)#
You can also go full policy-based, using tools like Open Policy Agent (OPA) or AWS Cedar, where you declare your access logic as code.
The process here can be more complex as you'll need to understand the policy languages and how they work. At Permit, we help you with this by building a layer of SDKs, APIs, and a GUI policy editor.
This means you can generate policy-as-code under the hood without manually writing policies from scratch. Below you can see Permit's policy UI, combining RBAC, ABAC, and ReBAC policies all together in one interface:
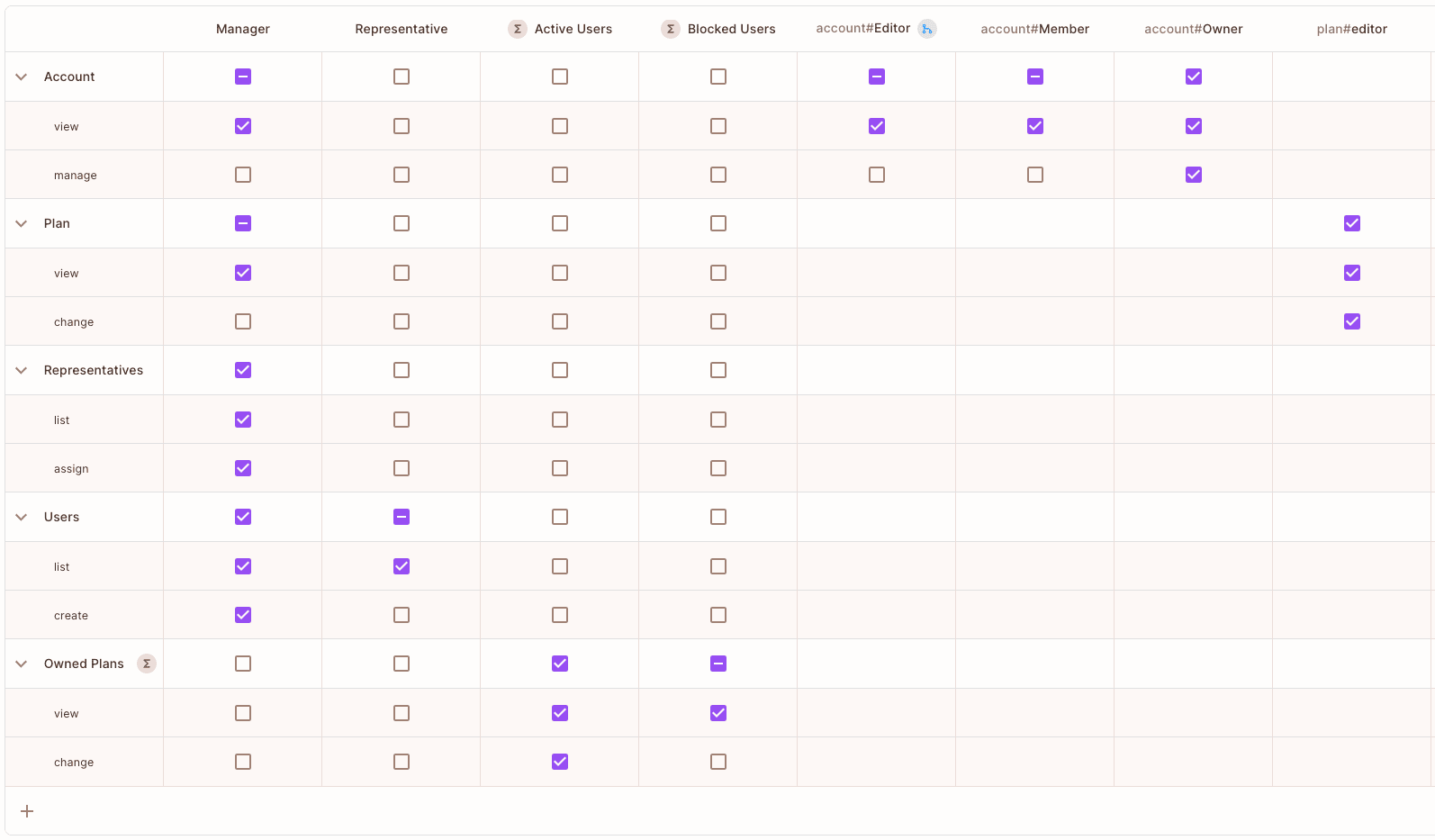
Instead of jumping straight into complex policy languages, you can start with simple SDK-based role modeling, like RBAC or ReBAC, and gradually extend it with custom policies written in Rego, Cedar, or other supported languages.
Data Considerations#
Lastly, another important factor when implementing fine-grained, externalized permissions is how your data influences your policy decisions-and how you keep it up to date for your users.
As we mentioned earlier, one key strategy is to have a centralized policy configuration, but decentralized data and enforcement.
OPAL, the open-source tool behind Permit.io's architecture, allows you to run a centralized server connected to a Git repository, where you store your policies-your fine-grained authorization rules.
OPAL then synchronizes those policies in a consistent, event-driven manner to all the Policy Decision Points (PDPs) deployed across your infrastructure.
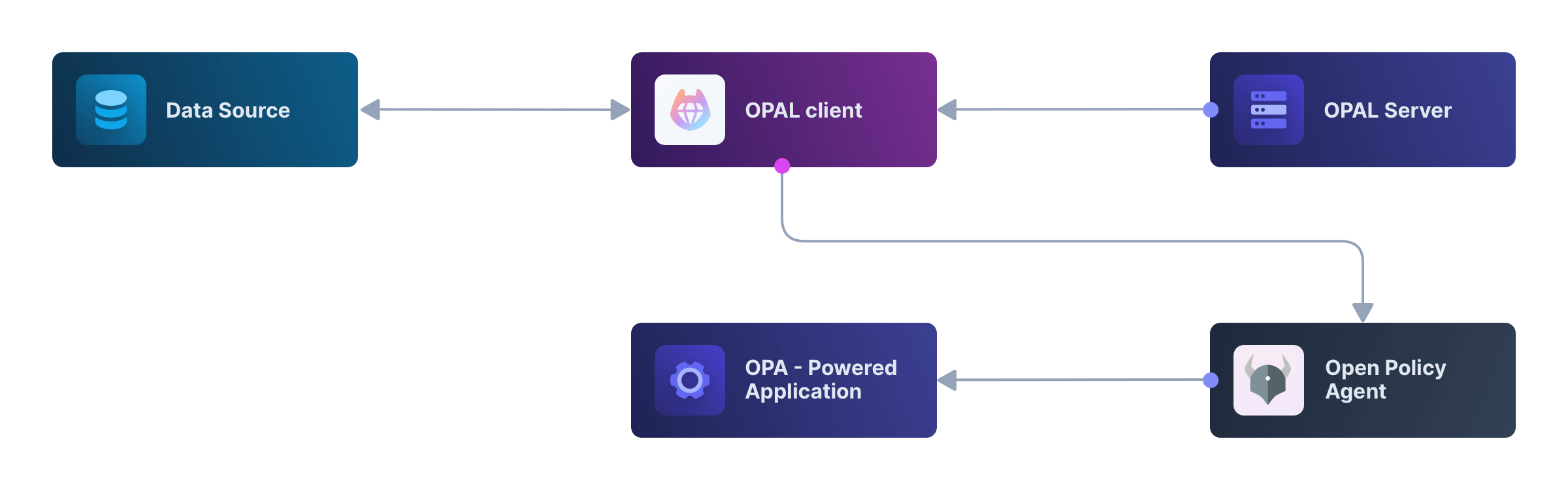
This means your policies stay centrally managed-via Git, APIs, or a GUI-but are enforced locally, right where your services live. You get the best of both worlds: central control and decentralized execution.
All of these models-RBAC, ABAC, ReBAC, and PBAC-depend on how and where authorization decisions are made. You can't just define policies-you need the right infrastructure to evaluate them efficiently and securely.
That brings us to what makes fine-grained access control possible: the Policy Decision Architecture.
Behind the Scenes: The Policy Decision Architecture#
Fine-grained authorization doesn't just mean more rules-it means building a smarter infrastructure. To get real-time, contextual decisions without slowing down your app, you need the right architecture behind the scenes.
That's why you need Policy Decision Points (PDPs).
Ready to upgrade your access model? Book a demo to learn how FusionAuth can enable dynamic, fine-grained authorization across modern stacks.
The Policy Decision Point#
PDPs are decentralized sidecars you deploy alongside your application services. Their job is to make authorization decisions close to where your code runs.
These sidecars can also synchronize the data needed for policy decisions in real-time (using tools like OPAL).
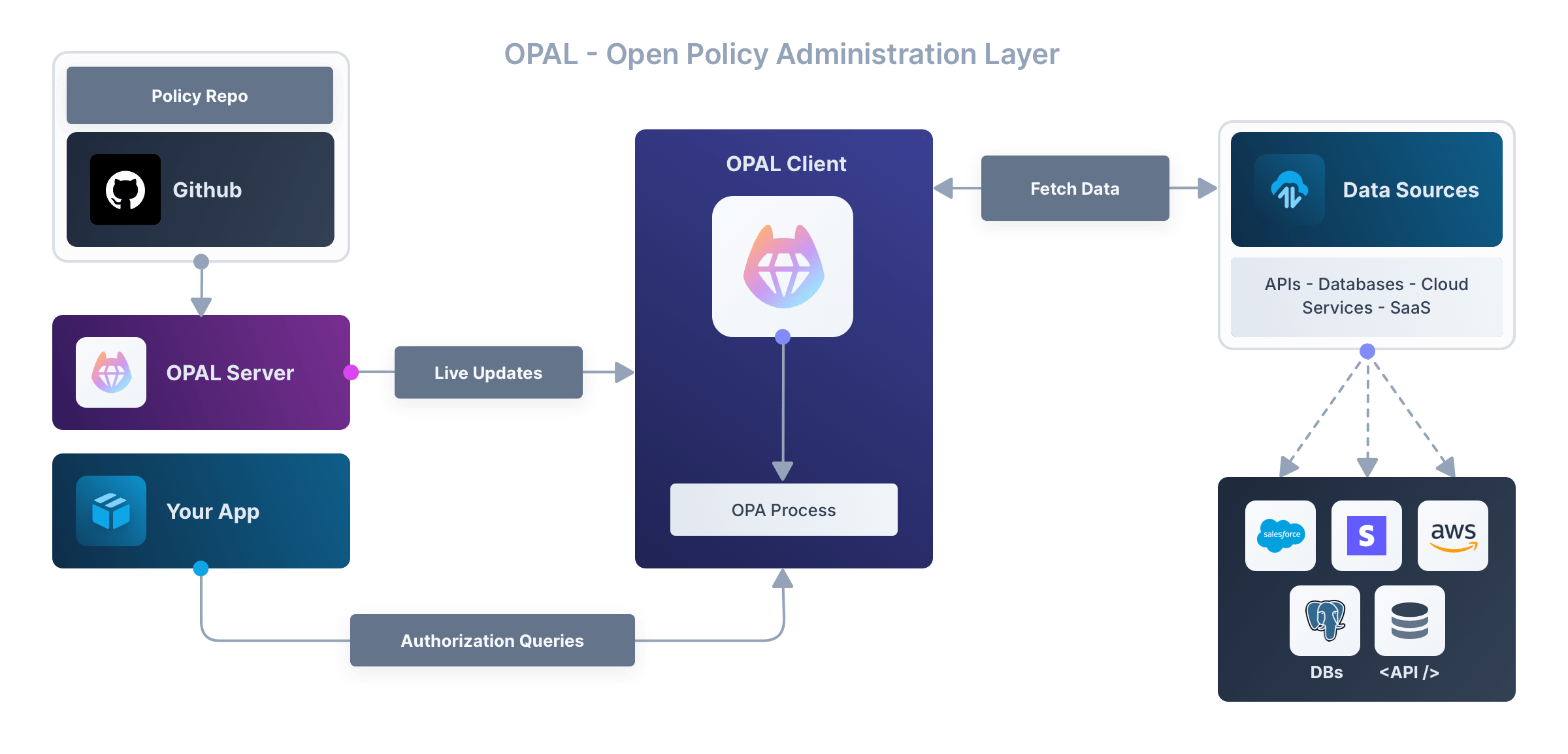
Because they're deployed at the edge, PDPs keep latency low: sub-10ms decisions, even with complex policies.
They stay continuously updated with:
- the latest policies
- real-time data (like roles, relationships, and attributes)
- dynamic context (like time, device, IP)
PDPs support multiple consistency models:
- eventual consistency (for flexibility)
- strong consistency (for safety)
- read-your-write consistency (for workflows that need immediate sync)
Every policy update is automatically synchronized to all the decentralized policy decision points, creating a fine-grained, decentralized system that still relies on a centralized source of truth for your policies-usually managed through Git or an admin UI.
How Does the PDP Work?#
When we make authorization decisions, we usually consider three arguments:
- user
- action
- resource
But to actually make a decision, there are three key components involved in the policy decision process: policies, data and context.
A policy is a set of abstract rules that define what a user is allowed-or not allowed-to do.
Policies don't rely on specific users or resources-instead, they use placeholders or schemas like "user", "role", "action", and "resource", defining the logic behind permission checks. Policies alone can't make a decision-they depend on data.
Data is the actual state of your application. It enables the policy engine to evaluate whether the abstract rules apply in a given situation. If your policy says: "A user with the role admin can delete documents", assigning the admin role to a user is data.
Data also includes:
- user attributes (e.g., location, team)
- resource attributes
- relationships (e.g., user-to-resource or resource-to-resource links)
The richer your data, the more powerful and flexible your fine-grained policies become.
The third component is context-the real-time, ephemeral information that isn't persistent data but is critical for certain decisions. For example:
- What time is the request made?
- What device is the user using?
- Is the user logging in from an unfamiliar location?
Context allows the decision engine to factor in real-world conditions-essential for truly dynamic and fine-grained decisions.
Policy, data, and context come together at the Policy Decision Point (PDP) to make real-time authorization decisions tailored to your application and users.
The Time to Shift Is Now#
We've crossed a threshold in how modern applications are built-and what users expect from them.
Monoliths have become distributed systems. One-size-fits-all roles have evolved into dynamic, data-driven access needs. Users aren't just consumers anymore-they're collaborators, owners, and privacy-conscious stakeholders.
That's why fine-grained authorization isn't a nice-to-have anymore-it's the natural next step in building secure, flexible, and user-centric applications.
The good news is that you don't need to start from scratch.
You can take what you already have-your RBAC roles, your assignment logic, your internal tooling-and lift and shift it into a future-ready model. Take these steps:
- add attributes to handle more nuanced access patterns
- introduce relationships to support collaboration and delegation
- externalize logic so it's fast, consistent, and easier to reason about
- use tools like Permit.io, FusionAuth, and OPAL to make real-time decisions without building everything yourself
The patterns are mature. The tools are ready. And the expectations are already here, so if you're still managing access with scattered conditionals and static roles, this is your sign: it's time to rethink how your app handles "who can do what."
With just a few operational steps, you can create a fully functional, secure, fine-grained access control system-offering your users a much better authorization experience.
Ready to upgrade your access model? Book a demo to learn how FusionAuth powers dynamic, fine-grained authorization across modern stacks.
This article was written for FusionAuth by Gabriel Manor, VP DevRel at Permit.io, a FusionAuth partner that specializes in fine-grained authorization.



