Understanding Model Context Protocol: Connecting Your Software To AI
By Simon Russell
When the first version of the Model Context Protocol (MCP) specification was released last November, it became a buzzword overnight. Like a lot of buzzwords, it gets thrown around so much that it tends to lose meaning. But it is actually a very specific thing, that's quite well defined; it's also probably the least "AI" part of modern AI. It's a definition of how one piece of software can talk to another – something that's going to be familiar to nearly every software engineer.
That simplicity does mask the fundamental shift that it represents though – it's similar to the move from desktop software to the web; or from the web to mobile apps. It's a new user interface: but it's more than that too. It's the first time a generalised approach to allowing AI agents to access software has been attempted.
If you're building software, understanding how MCP affects what you're building is essential. Users will grow to expect all software to work with the agent platforms they're using; to be able to be automated by those agents. Prefactor exists to close this gap and is focused on enabling builders to operate securely and at scale.
Prefactor's approach is grounded in our belief that thinking MCP is a nice-to-have integration layer is a mistake. Instead, it's an identity problem at scale. Every agent, every API, every human needs to be authenticated and controlled on the same footing — or you're just building the next generation of shadow IT.
How did we get to MCP?#
At this point, chatbot-style interfaces for interacting with large language models have become commonplace. While these models can be useful on their own, there are many situations where being able to use external tools makes sense.
The most common one is web search – most chatbot platforms will now search the web for you to get up-to-date information; without this you'd have to rely on whatever the facts were when their training data (often six to twelve months out of date). The possibility of hallucinations is also quite high, depending on the topic.
Early versions of this capability (circa 2022) had the model emit marked up calls in tool-specific formats; the issue with this was that the model would need to be trained to understand that specific tool and invocation format.
Over time this evolved into the more generic concept of "tools" – a description of the tool and the parameters. The LLM provider would split out the tool calls from normal text generation, to avoid ambiguity, and the agent framework would intercept these requests from the language model, perform the call, then add the result of the call to the conversation.
This solved the problem of "how should the LLM indicate it needs to call a tool", but the actual communication was still specific to a particular agent framework; each tool would need to be modified to use it with a different agent. To encourage the development of more tools, Anthropic realised a standardised API format would be needed, and created the Model Context Protocol at the end of 2024.
It's important to say that there's a lot more to MCP than just tool calls – but we'll focus on those since they're probably what most people are thinking about when they're thinking about MCP. And I mean if you're thinking "what about resources, prompts, elicitations and sampling" then you probably don't need to read this article...
A quick reminder on how LLMs work#
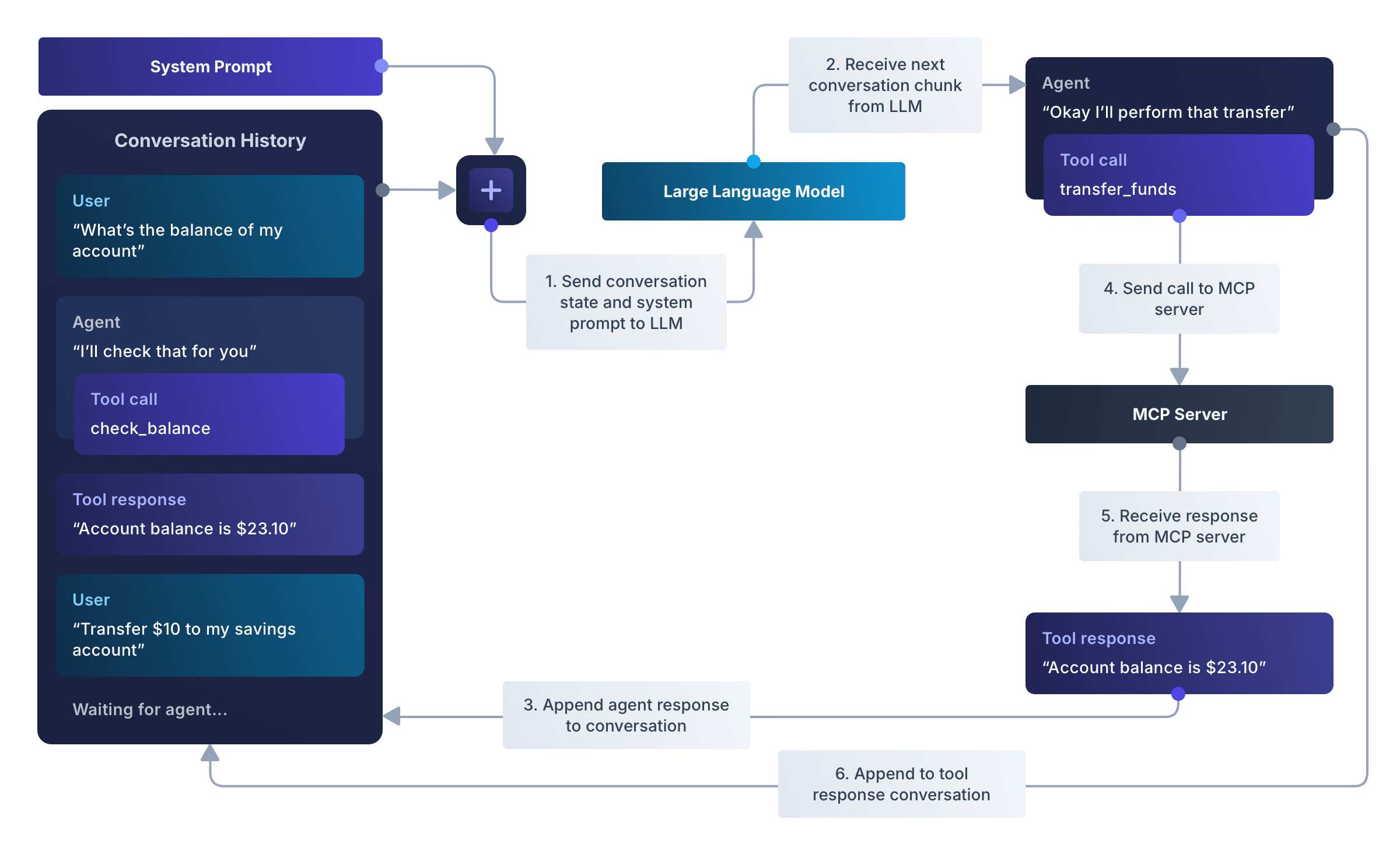
At this point, it's probably worth a reminder that large language models work by looking at a conversation, and asking "what would the agent say now". Each chunk of the conversation is marked with "user", "agent", or "tool response"; everything is represented within the conversation, as a single stream.
To figure out "who should speak next", you can look at the last chunk of the conversation:
- if it's a user or tool response, then the agent framework needs to use the LLM to generate an agent response
- if it's an agent response with a tool call, then the next step is to call the tools and wait for those responses
- if it's an agent response without tool calls, then wait for the user to continue the conversation.
(There can be more to it than this and error handling complicates it a little more, but this is the core of how an agent framework operates.)
Each time the agent framework wants to generate a response, it sends the entire conversation – including all previous user input, agent responses and tool responses. The model then generates the next agent chunk (which can contain more tool requests). The language model is stateless.
In addition to everything mentioned above, there's an implicit "system prompt" that instructs the model on how to act, what tools are available and what they do.
What's important to remember is that the language model doesn't call the MCP server directly – it's all driven by the agent framework. MCP isn't something that the language model cares about – it's how the agent framework actually implements the tool call.
But what actually is it?#
Before jumping into the lower-level details, it's probably worth discussing the high-level actors that the MCP specification mentions:
- the MCP host: this is the "agent framework" that we discussed previously; the part that's managing the LLM and the conversation
- the MCP client: manages a connection to an MCP server
- the MCP server: where the action happens. The server is the whole reason that MCP exists.
In practice the lines between client and host are somewhat blurry, and unless you're implementing that side the distinction is not that important.
The layers of MCP#
From top to bottom:
| Data layer | Primitives | The specification defines a set of JSON-RPC endpoints that can be called to perform tool calls and access other features. |
| JSON-RPC | Defines a simple remote procedure call protocol using JSON. It's a pretty short read, and some features like batching aren't supported in MCP. | |
| Transport layer | Specifies how the JSON-RPC calls will be made |
Let's look at the transport layers defined in the current version of the specification.
The stdio transport#
The simplest transport layer to understand is the "stdio" transport. This is also called "local".
This transport gets its name from the way it communicates with the server process. The MCP client will actually start a process on the same machine; the input and output handles from that process become the input and output for the JSON-RPC calls.
The HTTP streaming transport#
This is actually the second version of an HTTP transport in the short life of MCP – the earlier SSE transport was a little more complicated to implement. This is also called "remote".
Although it's called a streaming transport, in the simplest implementation it's a very simple 1:1 HTTP request to MCP request. There is an option to allow for responses and updates to stream back, but for a lot of servers it may not be necessary to worry about this.
A tool request via HTTP streaming#
While we won't dive too far into the details here, let's take a quick look at what a tool request looks like. This should give you a flavour of how MCP works.
The example tool is retrieving the contents of a todo list. (Note that some headers have been left out for clarity.)
POST /mcp HTTP/1.1
accept: application/json, text/event-stream
content-type: application/json
content-length: 181
{
"id": 8,
"jsonrpc": "2.0",
"method": "tools/call",
"params": {
"arguments": {
"todo_list_id": "6b0ea930-d4f7-4822-b7a1-19dc4a0f5770"
},
"name": "retrieve_todo_list"
}
}The server then responds:
HTTP/1.1 200 OK
content-type: application/json; charset=utf-8
{
"id": 8,
"result": {
"content": [
{
"type": "text",
"text": "# Todo list: Chores (id=6b0ea930-d4f7-4822-b7a1-19dc4a0f5770)\nWeb URL: /list/6b0ea930-d4f7-4822-b7a1-19dc4a0f5770\n\n\n## Items\n\n 0. [ ] Feed dogs (id=aceb4f43-ff34-4354-a38f-bc23d7aca2a7)\n 1. [ ] Buy groceries (id=ee300415-b16b-4b56-a1f7-09f0fd9aed14)\n 2. [ ] Make dinner (id=c74d9b80-40f2-4026-84fe-85b7effc4690)\n 3. [ ] Wash dishes (id=4d2e2990-972d-402f-be77-02055b1269c5)"
}
],
"isError": false
},
"jsonrpc": "2.0"
}Probably the most unexpected thing for people new to MCP is that the response there is actually in Markdown! But the LLM figures it out – it even understands the Github checkbox format to indicate which to-do items are completed.
Note that it doesn't have to be Markdown, it can be basically anything that an LLM can understand. Markdown is a common choice for LLMs as it has a little bit of semantic markup (headings, bullet lists etc) but without overwhelming the model with too much structure. The best approach is to use the minimum necessary – just imagine there's a person on the other end reading it.
There is also a structured response format in the June 2025 version of the spec which allows responses more like a traditional API. Support is mixed, though, and it isn't necessarily going to work better. Ultimately LLMs are designed to process text in a variety of formats and it is often more effective to embrace this.
It can be incredibly easy to graft an MCP server onto your application. It's not as complex or as formal as defining an API; you can make changes to the result format and the LLM will adapt.
That's cool, but where's the auth?!#
So glad you asked; yes that was quite a bit of scene-setting. Part of the reason for going into that detail was because auth happens at the transport layer – it's actually only currently defined for the HTTP streaming transport.
Why is auth important anyway?#
Auth isn't important for every MCP server. For example, a locally hosted stdio-based server that's accessing local files doesn't need credentials to do that.
As soon as that MCP server needs to access a protected system or is exposed on the internet, auth becomes important. Otherwise you don't know who is making what requests of your MCP server or if they are even allowed to do so. Before MCP Auth was added to the spec, this problem was solved in a variety of ways:
- for locally hosted servers: environment variables containing API tokens or popping up a browser to complete an OAuth flow
- for remote servers: custom headers and bearer tokens
MCP Auth formalised the use of bearer tokens, obtained using OAuth.
How is OAuth used in MCP?#
The access token obtained during an OAuth authorisation process becomes the bearer token sent to the server for each request. Because the MCP client undertakes this authorisation process on behalf of the MCP server, there are a few steps that need to be undertaken.
Only the first two steps are something that the MCP server actually implements – the rest is directly between the MCP client and the authorisation server.
- MCP client to MCP server
- Client receives a "401 Not Authorised" response: this response contains information pointing at a "resource metadata" document.
- MCP client fetches resource metadata from MCP server: this metadata contains a pointer to the authorisation server.
- MCP client to authorisation server
- MCP client fetches authorisation server metadata: this contains a lot of information about the OAuth setup, including the endpoint for Dynamic Client Registration.
- MCP client registers new dynamic client: this gives the client the credentials it can use to start the authorisation process
- Authorisation process
- MCP client sends user to authorisation URL: this starts the authorisation process
- User completes authorisation
- Authorisation server redirects back to client: this is the standard OAuth completion flow
- Client obtains access token
- MCP client to MCP server
- Client retries the initial request that failed: this time with the addition of the access token. Assuming everything went smoothly, this request will succeed.
Can any OAuth server be used with MCP?#
The short answer is "yes and no". The main blocking feature is the use of Dynamic Client Registration within the flow. Any OAuth server that supports both DCR and PKCE (much more common) is likely to technically work – but the actual experience may not be ideal.
Most OAuth servers weren't designed to have an unbounded number of clients registered, so there can be performance issues. There also isn't a way in the spec to cleanly expire registered clients.
Even if you could, for example, get a more general OAuth provider, like Google, to work directly with MCP there would be problems. The access tokens that are obtained from Google should not be sent to MCP clients directly, as they could be compromised via the MCP client. It's not quite as bad as storing access tokens in a web browser's local storage, but you don't have a lot of control over any tokens the MCP client has access to. The access tokens obtained should be locked to your MCP server.
Prefactor has been built from the ground up to implement MCP auth, and can wrap around your existing auth provider. MCP auth is a specifically supported profile, and things like dynamic client registration are designed to work at scale and not interfere with traditional clients. Using Prefactor, an existing MCP remote server can have auth running with minimal changes.
Authenticating to a backend API#
One area that tends to trip people implementing MCP servers up is authenticating from the MCP server to a backend API or service, where that request needs to be linked to the user authenticating with the MCP server.
One approach that works well is to use Token Exchange on the OAuth server. The MCP server exchanges the token it receives from the MCP client for a corresponding backend token. This token is managed and refreshed by the OAuth server.
Depending on the situation, the backend authentication process can be part of the auth process undertaken when the user first connects to the MCP server. This is implemented by the MCP auth server redirecting to the backend authorisation server, letting the user complete the auth flow there, and then the MCP auth server handling the redirect and tokens. This nested approach keeps the backend access tokens within the MCP authorisation server.
Prefactor implements both parts of this, so MCP servers can operate without embedded API keys or complex authorisation logic.
Coming up in the MCP specification#
The specification for MCP has gone through several iterations over the last year. The next version is scheduled to be released in November. From an authentication point of view, there are two interesting changes likely to be included: scopes and step-up auth.
Client implementations of these features may trail the specification. While clients tend to implement the core feature set, the less common features tend to be less well supported.
Scopes#
Currently the question of OAuth scopes is left unanswered in the spec. This has led to some confusion, and different implementations making different choices about what scopes should be included in the authorisation request. In the next version of the specification there will be a clear definition of how an MCP client should receive the correct set of scopes to include in the request.
Step-up auth#
Building on the scopes addition, it will now be possible for a server to indicate to the client that it requires additional permissions (represented by scopes) to continue. The client will start a new authorisation request with the additional scopes the server indicates are required. This allows for the initial set of permissions granted to be smaller, while still allowing for a full set of tools to be provided.
URL elicitation#
This addition allows the server to ask the user to visit a web page to complete a task. The task can be anything: approving an action or making a payment, for example. While this sounds similar to how auth works, it's implemented through a separate mechanism that doesn't affect the bearer token the client uses to connect.
MCP auth in the longer term#
There are a few interesting areas where the MCP specification will likely head over the coming years. Some of these are closer than others, and some are quite complex to solve.
Deeper tool metadata#
There are several problems with the current way tools are described to the client:
- it's a flat list: there's no grouping of tools, so there can be redundancy in the way they're described, confusing the LLM
- it's a list that should be short: LLMs (like humans) don't like to be confronted with a huge list of tools.
- tool visibility: should a tool that's unavailable currently (due to permissions, or other circumstances) be visible to the client? Should it be told what actions can be taken to make the tool available?
Some of these problems are leading to "supertools" – basically, combining a set of tools into a single tool. Perhaps this approach will be formalised.
Seamless auth within enterprises (and into third-party systems)#
The current specification for MCP auth works well both externally and internally, but it does introduce friction that could be removed. An enterprise wants to control the agent platform and the set of MCP servers it can access; it makes sense that they would also want to control permissions and identities between these systems as well.
For example, an enterprise user accessing a third-party MCP server shouldn't have to (or be able to) decide which account in the third-party system corresponds to their account. It's a similar problem to how SSO was solved in enterprises previously.
Autonomous agent access#
Currently MCP auth is really user auth. The agent that is acting on behalf of the user doesn't have an identity of its own; it can't be assigned permissions independently of the user. This becomes problematic when there is no user – for example, a nightly task that creates a report.
Ideally that agent would be identified and granted permissions to access what it needs, without a human identity being necessary. Both the identity mechanism and the authentication mechanism need to be defined.
Wrapping up#
MCP represents a platform shift as significant as the move to web or mobile – but with a much lower barrier to entry. The authentication layer, while still maturing, is already production-ready, and upcoming additions like scopes and step-up auth show the specification is evolving based on real-world needs.
For developers, the takeaway is simple: users will soon expect all software to work with their AI agents. The good news is that MCP's simplicity makes integration straightforward. Start with basic tool exposure, add OAuth when you need user context, and evolve your auth patterns as requirements grow.
The question isn't whether to adopt MCP – it's how quickly you can integrate it before your users start wondering why your software doesn't work with their agents.